AWS Big Data Blog
Tag: Amazon Athena

Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started). In AWS ProServe-led customer engagements, the use cases we work on usually come with technical complexity and scalability requirements. In this post, we discuss a common use case in relation to operational data processing and the solution we built using Apache Hudi and AWS Glue.

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Access Amazon Athena in your applications using the WebSocket API
In this post, we present a solution that can integrate with your front-end application to query data from Amazon S3 using an Athena synchronous API invocation. With this solution, you can add a layer of abstraction to your application on direct Athena API calls and promote the access using the WebSocket API developed with Amazon API Gateway. The query results are returned back to the application as Amazon S3 presigned URLs.

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Use Amazon Athena and Amazon QuickSight in a cross-account environment
This blog post was last reviewed and updated May, 2022 to include AWS Lake Formation resource sharing model. Many AWS customers use a multi-account strategy to host applications for different departments within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach, which raises challenges when you need to use […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
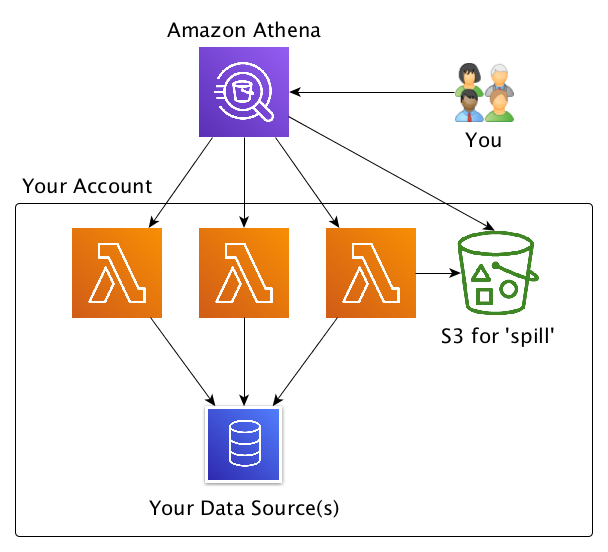
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

Optimize Python ETL by extending Pandas with AWS Data Wrangler
April 2024: This post was reviewed for accuracy. Developing extract, transform, and load (ETL) data pipelines is one of the most time-consuming steps to keep data lakes, data warehouses, and databases up to date and ready to provide business insights. You can categorize these pipelines into distributed and non-distributed, and the choice of one or […]
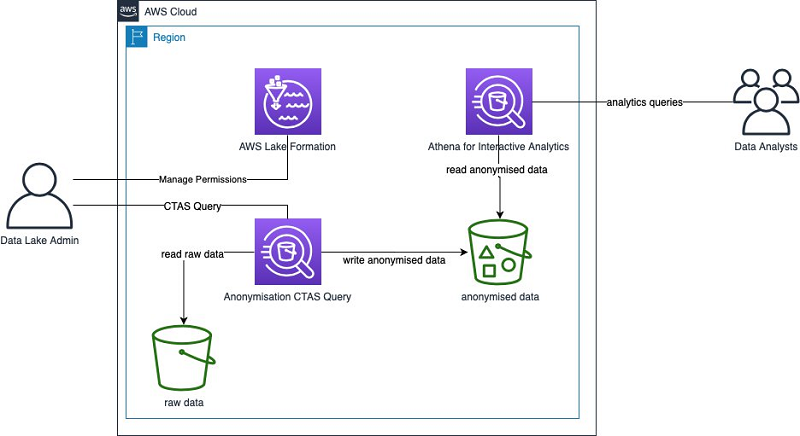
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.