AWS Compute Blog
Using EC2 Auto Scaling predictive scaling policies with Blue/Green deployments
This post is written by Ankur Sethi, Product Manager for EC2.
Amazon EC2 Auto Scaling allows customers to realize the elasticity benefits of AWS by automatically launching and shutting down instances to match application demand. Earlier this year we introduced predictive scaling, a new EC2 Auto Scaling policy that predicts demand and proactively scales capacity, resulting in better availability of your applications (if you are new to predictive scaling, I suggest you read this blog post before proceeding). In this blog, I will walk you through how to use a new feature, predictive scaling custom metrics, to configure predictive scaling for an application that follows a Blue/Green deployment strategy.
Blue/Green Deployment using Auto Scaling groups
The fundamental idea behind Blue/Green deployment is to shift traffic between two environments that are running different versions of your application. The Blue environment represents your current application version serving production traffic. In parallel, the Green environment is staged running the newer version. After the Green environment is ready and tested, production traffic is redirected from Blue to Green either all at once or in increments, similar to canary deployments. At the end of the load transfer, you can either terminate the Blue Auto Scaling group or reuse it to stage the next version update. Irrespective of the approach, when a new Auto Scaling group is created as part of Blue/Green deployment, EC2 Auto Scaling, and in turn predictive scaling, does not know that this new Auto Scaling group is running the same application that the Blue one was. Predictive scaling needs a minimum of 24 hours of historical metric data and up to 14 days for the most accurate results, neither of which the new Auto Scaling group has when the Blue/Green deployment is initiated. This means that if you frequently conduct Blue/Green deployments, predictive scaling regularly pauses for at least 24 hours, and you may experience less optimal forecasts after each deployment.
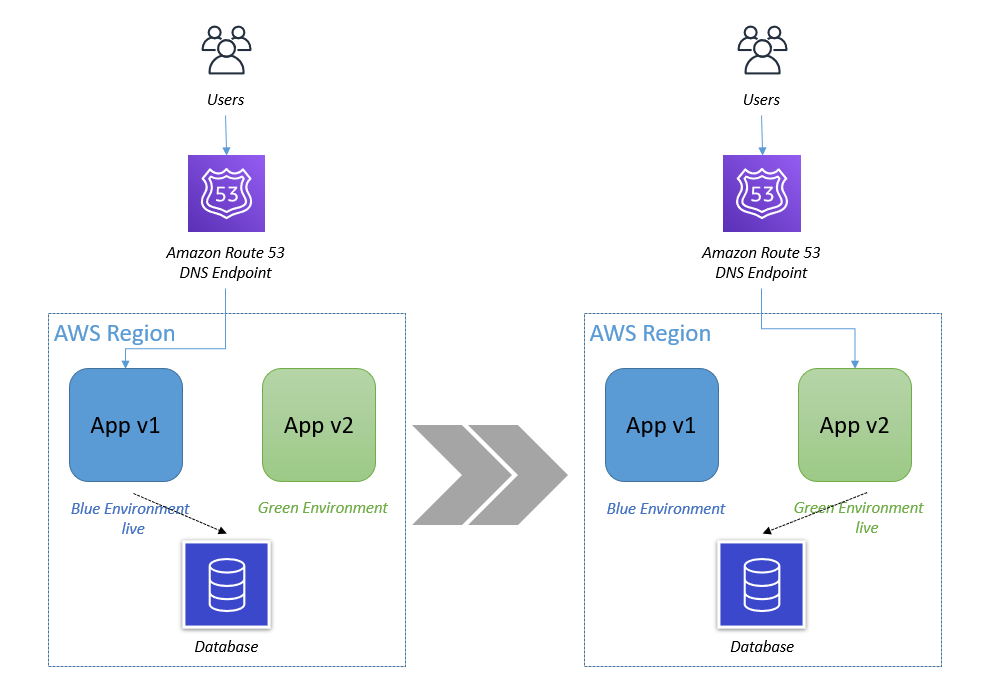
Figure 1. In Blue/Green deployment you have two Auto Scaling groups running different versions of an application. You switch production traffic from Blue to Green to make the updated version public.
How to retain your application load history using predictive scaling custom metrics
To make predictive scaling work for Blue/Green deployment scenarios, we need to aggregate load metrics from both Blue and Green environments before using it to forecast capacity as depicted in the following illustration. The key benefit of using the aggregated metric is that, throughout the Blue/Green deployment, predictive scaling can continue to forecast load correctly without a pause, and it can retain the entire 14 days of data to provide the best predictions. For example, if your application observes different patterns during a weekday vs. a weekend, predictive scaling will be able to retain knowledge of that pattern after the deployment.
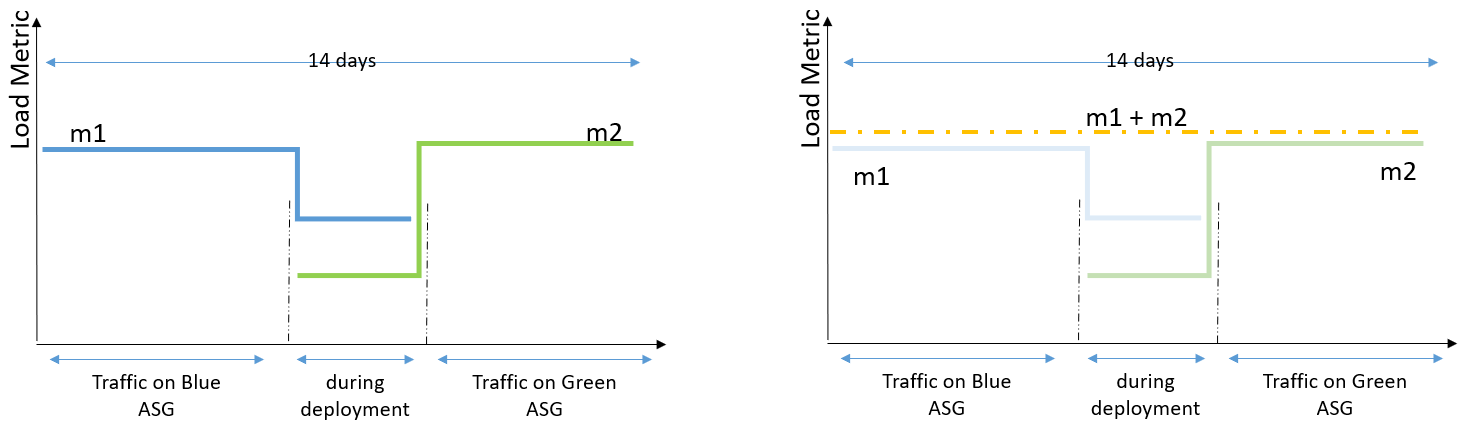
Figure 2. The aggregated metrics of Blue and Green Auto Scaling groups give you the total load traffic of an application. Predictive scaling gives most accurate forecasts when based on last 14 days of history.
Example
Let’s explore this solution with an example. I created a sample application and load simulation infrastructure that you can use to follow along by deploying this example AWS CloudFormation Stack in your account. This example deploys two Auto Scaling groups: ASG-myapp-v1 (Blue) and ASG-myapp-v2 (Green) to run a sample application. Only ASG-myapp-v1 is attached to a load balancer and has recurring requests generated for its application. I have applied a target tracking policy and predictive scaling policy to maintain CPU utilization at 25%. You should keep this Auto Scaling group running for at least 24 hours before proceeding with the rest of the example to have enough load generated for predictive scaling to start forecasting.
ASG-myapp-v2 does not have any requests generated of its own. In the following sections, to highlight how metric aggregation works, I will apply a predictive scaling policy to it using Custom Metric configurations aggregating CPU Utilization metrics of both Auto Scaling groups. I’ll then verify if the forecasts are generated for ASG-myapp-v2 based on the aggregated metrics.
As part of your Blue/Green deployment approach, if you alternate between exactly two Auto Scaling groups, then you can use simple math expressions such as SUM (m1, m2) where m1 and m2 are metrics for each Auto Scaling group. However, if you create new Auto Scaling groups for each deployment, then you need to refer to the metrics of all the Auto Scaling groups that were used to run the application in the last 14 days. You can simplify this task by following a naming convention for your Auto Scaling groups and leveraging the Search expression to select the required metrics. The naming convention is ASG-myapp-vx where we name the new Auto Scaling group according to the version number (ASG-myapp-v1 → ASG-myapp-v2 and so on). Using SEARCH(‘ {Namespace, DimensionName1, DimensionName2} SearchTerm’, ‘Statistic’, Period) expression I can identify the metrics of all the Auto Scaling groups that follow the name according to the SearchTerm. I can then aggregate the metrics by appending another expression. The final expression should look like SUM(SEARCH(…).
Step 1: Apply predictive scaling policy to Green Auto Scaling group ASG-myapp-v2 with custom metrics
To generate forecasts, the predictive scaling algorithm needs three metrics as input: a load metric that represents total demand on an Auto Scaling group, the number of instances that represents the capacity of the Auto Scaling groups, and a scaling metric that represents the average utilization of the instances in the Auto Scaling groups.
Here is how it would work with CPU Utilization metrics. First, create a scaling configuration file where you define the metrics, target value, and the predictive scaling mode for your policy.
cat predictive-scaling-policy-cpu.json
{
"MetricSpecifications": [
{
"CustomizedScalingMetricSpecification": {
},
"CustomizedLoadMetricSpecification": {
},
"CustomizedCapacityMetricSpecification": {
}
}
],
"Mode": "ForecastOnly"
}
EoF
I’ll elaborate on each of these metric specifications separately in the following sections. You can download the complete JSON file in GitHub.
Customized Load Metric Specification: You can aggregate the demand across your Auto Scaling groups by using the SUM expression. The demand forecasts are generated every hour, so this metric has to be aggregated with a time period of 3600 seconds.
"CustomizedLoadMetricSpecification": {
"MetricDataQueries": [
{
"Id": "load_sum",
"Expression": "SUM(SEARCH('{AWS/EC2,AutoScalingGroupName} MetricName=\"CPUUtilization\" ASG-myapp', 'Sum', 3600))"
}
]
}
Customized Capacity Metric Specification: Your customized capacity metric represents the total number of instances across your Auto Scaling groups. Similar to the load metric, the aggregation across Auto Scaling groups is done by using the SUM expression. Note that this metric has to follow a 300 seconds interval period.
"CustomizedCapacityMetricSpecification": {
"MetricDataQueries": [
{
"Id": "capacity_sum",
"Expression": "SUM(SEARCH('{AWS/AutoScaling,AutoScalingGroupName} MetricName=\"GroupInServiceIntances\" ASG-myapp', 'Average', 300))"
}
]
}
Customized Scaling Metric Specification: Your customized scaling metric represents the average utilization of the instances across your Auto Scaling groups. We cannot simply SUM the scaling metric of each Auto Scaling group as the utilization is an average metric that depends on the capacity and demand of the Auto Scaling group. Instead, we need to find the weighted average unit load (Load Metric/Capacity). To do so, we will use an expression: Sum(load)/Sum(capacity). Note that this metric also has to follow a 300 seconds interval period.
"CustomizedScalingMetricSpecification": {
"MetricDataQueries": [
{
"Id": "capacity_sum",
"Expression": "SUM(SEARCH('{AWS/AutoScaling,AutoScalingGroupName} MetricName=\"GroupInServiceIntances\" ASG-myapp', 'Average', 300))"
"ReturnData": "False"
},
{
"Id": "load_sum",
"Expression": "SUM(SEARCH('{AWS/EC2,AutoScalingGroupName} MetricName=\"CPUUtilization\" ASG-myapp', 'Sum', 300))"
"ReturnData": "False"
},
{
"Id": "weighted_average",
"Expression": "load_sum / (capacity_sum * PERIOD(capacity_sum) / 60)"
}
]
}
Once you have created the configuration file, you can run the following CLI command to add the predictive scaling policy to your Green Auto Scaling group.
aws autoscaling put-scaling-policy \ --auto-scaling-group-name "ASG-myapp-v2" \ --policy-name "CPUUtilizationpolicy" \ --policy-type "PredictiveScaling" \ --predictive-scaling-configuration file://predictive-scaling-policy-cpu.json
Instantaneously, the forecasts will be generated for the Green Auto Scaling group (My-ASG-v2) as if this new Auto Scaling group has been running the application. You can validate this using the predictive scaling forecasts API. You can also use the console to review forecasts by navigating to the Amazon EC2 Auto Scaling console, selecting the Auto Scaling group that you configured with predictive scaling, and viewing the predictive scaling policy located under the Automatic Scaling section of the Auto Scaling group details view.
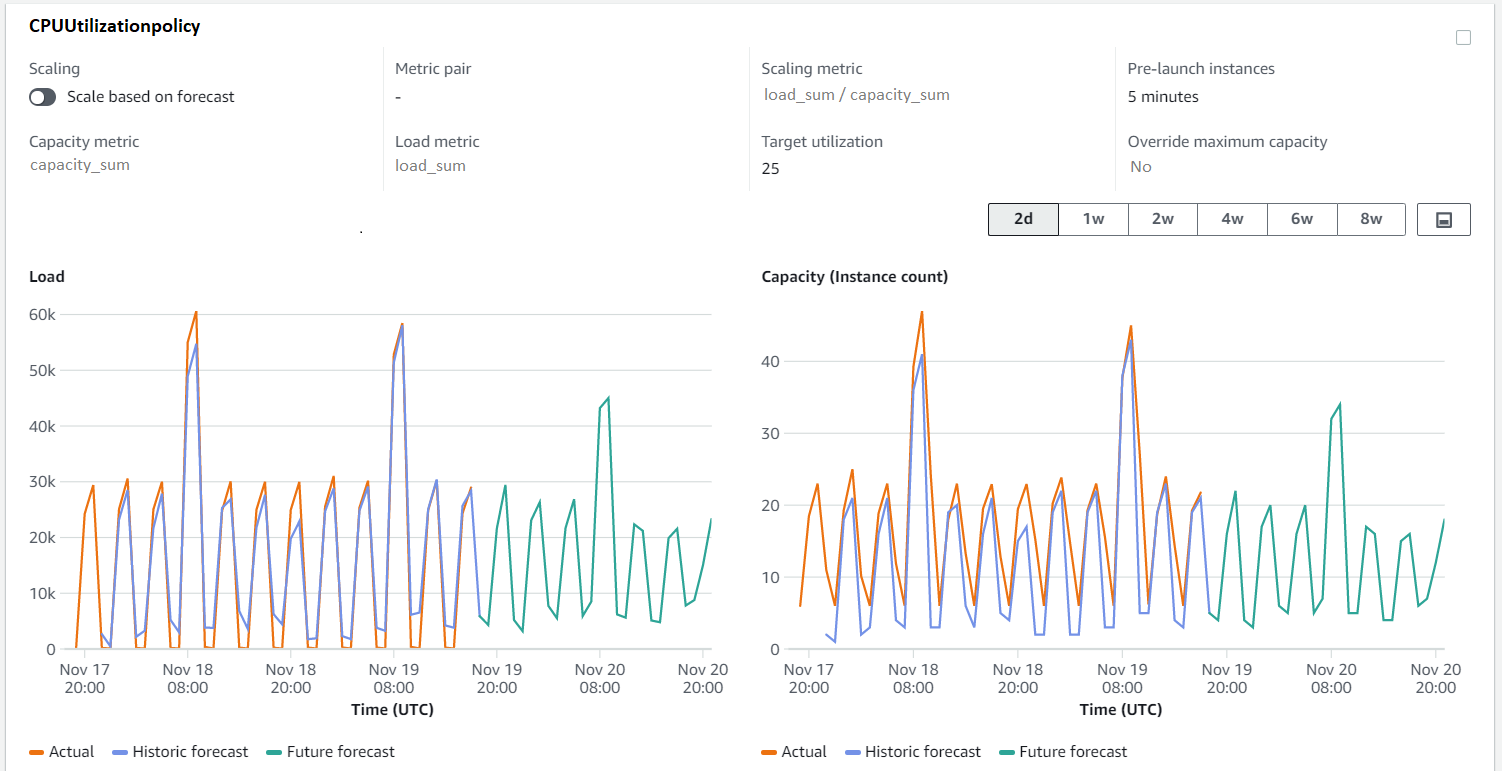
Figure 3. EC2 Auto Scaling console showing capacity and load forecasts for Green Auto Scaling group. The forecasts are generated as if this Auto Scaling group has been running the application from the beginning.
Step 2: Terminate ASG-myapp-v1 and see predictive scaling forecasts continuing
Now complete the Blue/Green deployment pattern by terminating the Blue Auto Scaling group, and then go to the console to check if the forecasts are retained for the Green Auto Scaling group.
aws autoscaling delete-auto-scaling-group \ --auto-scaling-group-name ASG-myapp-v1
You can quickly check the forecasts on the console for ASG-myapp-v2 to find that terminating the Blue Auto Scaling group has no impact on the forecasts of the Green one. The forecasts are all based on aggregated metrics. As you continue to do Blue/Green deployments in future, the history of all the prior Auto Scaling groups will persist, ensuring that our predictions are always based on the complete set of metric history. Before we conclude, remember to delete the resources you created. As part of this example, to avoid unnecessary costs, delete the CloudFormation stack.
Conclusion
Custom metrics give you the flexibility to base predictive scaling on metrics that most accurately represent the load on your Auto Scaling groups. This blog focused on the use case where we aggregated metrics from different Auto Scaling groups across Blue/Green deployments to get accurate forecasts from predictive scaling. You don’t have to wait for 24 hours to get the first set of forecasts or manually set capacity when the new Auto Scaling group is created to deploy an updated version of the application. You can read about other use cases of custom metrics and metric math in the public documentation such as scaling based on queue metrics.