AWS Big Data Blog
Author: Ben Snively

Restrict access to your AWS Glue Data Catalog with resource-level IAM permissions and resource-based policies
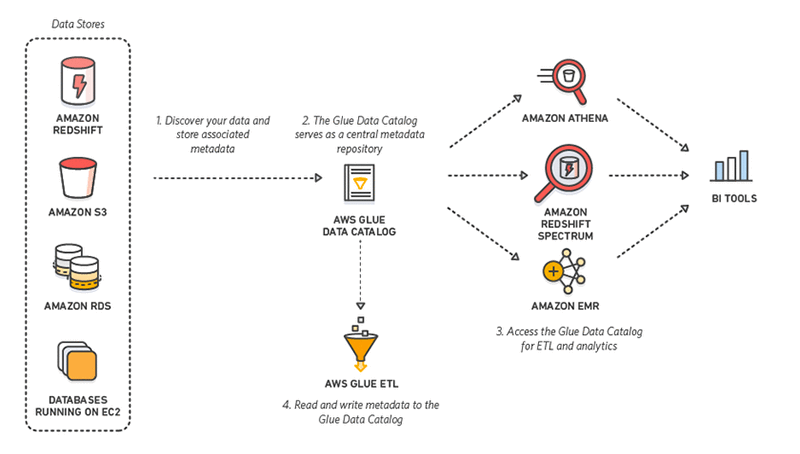
Data cataloging is an important part of many analytical systems. The AWS Glue Data Catalog provides integration with a wide number of tools. Using the Data Catalog, you also can specify a policy that grants permissions to objects in the Data Catalog. Data lakes require detailed access control at both the content level and the level of the metadata describing the content. In this post, we show how you can define the access policies for the metadata in the catalog.
Harmonize, Query, and Visualize Data from Various Providers using AWS Glue, Amazon Athena, and Amazon QuickSight
Have you ever been faced with many different data sources in different formats that need to be analyzed together to drive value and insights? You need to be able to query, analyze, process, and visualize all your data as one canonical dataset, regardless of the data source or original format. In this post, I walk […]

Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Ben Snively is a Solutions Architect with AWS Speed and agility are essential with today’s analytics tools. The quicker you can get from idea to first results, the more you can experiment […]

Using Spark SQL for ETL
Ben Snively is a Solutions Architect with AWS With big data, you deal with many different formats and large volumes of data. SQL-style queries have been around for nearly four decades. Many systems support SQL-style syntax on top of the data layers, and the Hadoop/Spark ecosystem is no exception. This allows companies to try new […]
Combine NoSQL and Massively Parallel Analytics Using Apache HBase and Apache Hive on Amazon EMR
Ben Snively is a Solutions Architect with AWS Jon Fritz, a Senior Product Manager for Amazon EMR, co-authored this post With today’s launch of Amazon EMR release 4.6, you can now quickly and easily provision a cluster with Apache HBase 1.2. Apache HBase is a massively scalable, distributed big data store in the Apache Hadoop ecosystem. It is […]
Securely Access Web Interfaces on Amazon EMR Launched in a Private Subnet
Ben Snively is a Solutions Architect with AWS Private subnets allow you to limit access to deployed components, and to control security and routing of the system. You can also use a private subnet to connect an on-premises local network to AWS through a VPN or AWS Direct Connect. Amazon EMR allows customers to launch […]