亚马逊AWS官方博客
使用 AWS ParallelCluster 运行 Ansys Fluent 的最佳实践
使用 HPC(高性能计算)应对计算流体动力学 (CFD) 的挑战已成为惯例。随着近一二十年间,HPC 工作站向超级计算机的发展变缓,计算集群正不断地取代单独的大型 SMP(共享内存处理)超级计算机的地位,并且已成为“新常态”。另外,一项更加新的创新——云技术,同样也大幅提升了总的计算吞吐量。
这一篇博文将向您介绍在数分钟内于运行 Ansys Fluent(一款市售的计算流体动力学软件包)的 AWS 上完成 HPC 集群设置的最佳优良实践。此外您还能看到一些安装 Ansys Fluent 并运行您的首个作业的示例脚本。“最佳指南”是一种相对称呼,在云技术中更是如此,因为存在能以不同方式组合达成相同目的的诸多可能性(亦称为服务)。仅在需要使用特定的应用程序特性或应用程序功能的情况下,才能判定某种选择是否优于另一种。举例来说,“高性能并行文件系统 (Amazon FSx) 优于 NFS 共享”这一判断在绝大部分 HPC 工作负载中是成立的,但在另一些情形中(例如 !I/O 密集型应用程序,或者创建小型 HPC 集群来运行少量和/或小型作业)NFS 共享已经绰绰有余,并且此种方式更加廉价,设置简单。在此篇博文中我们将分享我们视作最佳优良实践的方法,以及其他一些您在实践中可能会考虑的可用替代选择。
我们将会使用的主要集群组件是以下的 AWS 服务:
- AWS ParallelCluster,这是一种 AWS 支持的开源集群管理工具,可用于在 AWS 云中部署并管理 HPC集群。
- 新的 AWS C5n 实例最多可使用 100 Gbps 的网络带宽。
- Amazon FSx for Lustre,这是一种高度并行文件系统,支持对 PB 级别的文件系统进行亚毫秒级别的访问,可为每 1TiB 的预置容量以 10,000 IOPS 的速度提供 200 MB/s 的聚合吞吐量。
- Nice DCV 用作远程可视化协议。
注:我们在 re:Invent 2018 上发布了 Elastic Fabric Adapter (EFA),最近又在多个 AWS 区域中推出了该服务。EFA 这种网络设备可挂载到您的 Amazon EC2 实例以加速 HPC 应用程序的运行,降低延迟并使其更均匀,带来比基于云的 HPC 系统通常使用的 TCP 传输方式更高的吞吐量。其提升了对于扩展 HPC 应用程序至关重要的实例间通信的性能,并为在现有 AWS 网络基础设施上运行做了优化。Ansys Fluent 尚不适合与 EFA 共用,因此本篇博文中不会全面介绍这一具体的网络设备。
注意:ANSYS Fluent 是一款需要许可证的市售软件包。本文假定您已获得在 AWS 上使用(或通过 AWS 访问)Ansys Fluent 的许可证。此外,下文的安装脚本还需要您拥有 Ansys 安装包 。您可以在“下载 – 当前发行版本”下方下载当前发行版本的 Ansys。
第一步:创建一个自定义 AMI
为了加速集群的创建,更重要的是,为了缩短计算节点的启动时间,良好做法是创建一个部分软件包已预安装并且设置已完成配置的自定义 AMI。
- 以已有 AMI 为基础开始工作,记下您计划部署集群区域的适用 AMI ID,详情请见我们的 AMI 区域列表。例如,我们在弗吉尼亚州 (us-east-1) 使用 CentOS7 开始工作,则 AMI ID 为
ami-0a4d7e08ea5178c02。 - 打开 AWS 控制台并在偏好区域(即选择 AMI 的区域)中启动一个实例,按前述方式使用 AMI ID。
- 确保您的实例可以从互联网访问,并且具有公共 IP 地址。
- 为实例分配一个允许其从 S3(或从特定的 S3 存储桶)下载文件的 IAM 角色。
- 可选择标记实例(即 Name = Fluent-AMI-v1)。
- 配置安全组以允许端口 22 上的入站连接。
- 如果您需要为 AWS ParallelCluster 创建自定义 AMI 方法的额外细节,请参阅官方文档 Building a custom AWS ParallelCluster AMI。
- 实例就绪后,通过 SSH 进行连接并以 root 身份运行以下命令:
现在您可以通过 AWS CLI(或 AWS Web 控制台)创建您的 AMI 了:
输出将如下所示:
记住 AMI id。稍后 AWS ParallelCluster 配置文件中将会用到。
创建/复用 VPC、子网以及安全组
下一步,创建或复用已有 VPC。注意 vpc-ID 和 subnet-ID。有关为 AWS ParallelCluster 创建并配置 VPC 方法的更多信息,可参阅网络配置。
您可以使用单个子网同时用于主实例和计算实例,或者使用两个子网:一个公共子网上为主实例,一个私有子网上为计算实例。
下方的配置文件展示了在单个子网上运行集群的方法,如此架构图所示:
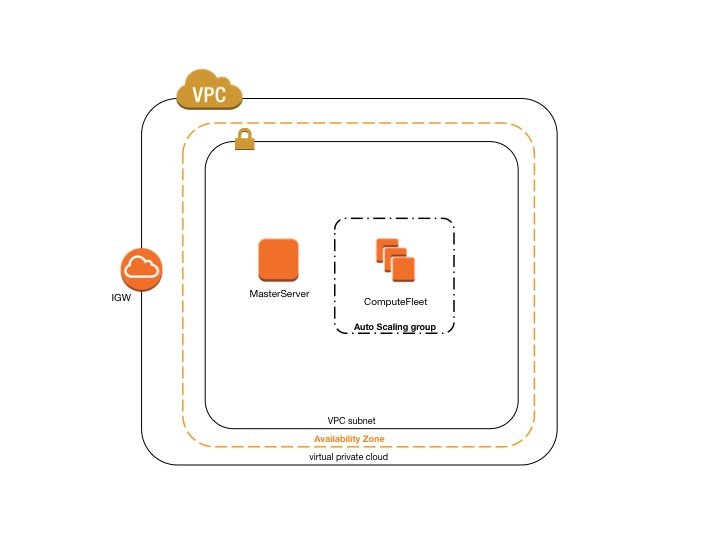
还要创建一个开启 8443 端口的临时安全组。这将用于允许与使用 NICE DCV 作为远程桌面流协议的主节点建立入站连接。
创建集群配置文件和后安装脚本
现在您可以开始编写配置文件了。在您本地 PC 上打开一个文本文件,并将下方代码粘贴进去。(此处为示例,您可能要依照偏好修改其中一些参数。您还要将占位符 <XXX> 替换为您自己的设置。)
让我们来详细研究一下该配置中的某些设置:
- aws_region_name = 选择正确的 AWS 区域对于您远程桌面会话的可用性至关重要:您与所选区域的地理距离越近,网络延迟就越低,可用性和交互性也就越好。如果您不清楚距您最近的 AWS 区域,可使用简单的 CloudPing 服务来确定哪个区域的延迟最低。
- initial_queue_size=0。此设置用于定义集群的初始大小。在此示例中其值为 0(您可以根据自己的需要任意修改)。0 意味着当您首次提交作业时,您的作业在队列中将处于待处理状态。当在集群中添加节点时,作业将转变为运行状态。AWS ParallelCluster 默认情况下会每 5 分钟检视一次计划程序队列,并根据运行待处理作业所需的槽数添加(或删除)节点。
- compute_instance_type = c5n.18xlarge。此设置用于定义集群计算节点的实例类型。此配置文件显示为 c5n.18xlarge。这是(在撰文时)最适合紧密耦合工作负载的实例。C5n.18xlarge 具有最佳的价格/性能比,及最佳的内存/核心比,还有一点很重要的是,它可用于 EFA。其他适用的实例是(最新的)c5.24xlarge 和 c4.8xlarge,两者价格都与 C4n.18xlarge 相近,但不支持 EFA。如果您想要构建自己的网格,并且需要更高的内存/核心比,m5.24xlarge 或 r5.24xlarge 是不错的选择,但其价格存在差异。最后,由于使用了定制的 Intel® Xeon® 可扩展处理器(可维持最高为 4.0 GHz 的全核频率),z1d.12xlarge 实例可以发挥出最大的效能,是所有云实例中速度最快的。不管实例类型为何,我们的建议是始终为所有实例类型选择最大大小。一般而言,紧密耦合工作负载的可扩展性受限于网络带宽(及延迟),因此为您的实例选择最大大小,可以通过每一个单独实例使用尽可能多的核心来减少跨节点通信。
- master_instance_type = g3.4xlarge。此设置用于定义集群主节点(或登录节点)的实例类型。在此示例中,我们选择配有 GPU (Nvidia M60) 的实例,因为我们还想要在作业完成之后进行数据后处理。后处理应用通常需要一个 GPU 来渲染复杂的 3D 图像。如果您不想执行任何后处理(或者您的后处理不需要 GPU),则可以选择与计算节点相同的实例类型(可能只是大小略小),或者您可以选择适合构建网格的实例类型(m5.24xlarge 或 r5.24xlarge)。
- placement_group = DYNAMIC 和 placement = compute 两者用于告知 AWS 我们想要使用集群置放组,以及只有计算节点需要位于相同的置放组中,主节点不需要。在启用 NFS 共享,计算节点与主节点之间的延迟需要尽可能低时,将主节点也放置于相同的置放组中是一种良好做法。在我们示例中,我们不使用 NFS 共享,而是使用 FSx。
- extra_json = { “cluster” : {“cfn_scheduler_slots” : “cores” } } 此语句连同下方后安装脚本开头的 for 循环一起用于禁用超线程。绝大部分的 HPC 应用程序无法从超线程中获益。但是,如果禁用超线程而不使用此行语句,SGE 将无法正确地将槽映射到核。
- custom_ami = ami-<AMI-ID> 该设置将告知 AWS ParallelCluster 使用您先前创建的 AMI。
- [fsx parallel-fs] 该部分包含定义您的基于 FSx 的并行高性能文件系统的设置。
- post_install = s3://<Your-S3-Bucket>/fluent-post-install.sh.该设置定义在所有实例创建之后,在实例上运行的脚本的位置。下方是一个针对此处案例调整过的脚本示例;您可以原样使用,也可以根据需要进行修改:
注:将占位符 <YourPassword> 替换为您自己的密码。该密码将仅用于通过 NICE DCV 执行连接。要通过 SSH 进行连接,您仍然需要使用配置文件中定义的私有密钥。
注:目前所提及的一些服务,尤其是 FSx 和 C5n,都是非常新的服务,它们可能只能用于某些区域。请查看区域表格来了解您偏好的区域是否拥有所有必要的服务。如果 C5n 不可用,可选择 C4.8xlarge 或 C5.18xlarge。如果 FSx 不可用,则使用 NFS 共享,不使用 EBS。下方的示例代码片段启用了 NFS 共享,而没有使用 IO1 卷类型。IO1 是一种 I/O 密集型高性能 SSD 卷,用于提供最高为 50 IOPS/GB(最大为 64,000 IOPS)的一致基线性能,每卷最高可提供 1,000 MB/s 的吞吐量(即 1TB 最高可提供 50,000 IOPS)。您也可以将 GP2 视作一种成本更低的替代方案,它具有数毫秒的延迟,提供 3 IOPS/GB 的一致基线性能(最低 100 IOPS),最大 16,000 IOPS,每卷可提供最高为 250 MB/s 的吞吐量。参阅 ParallelCluster 文档的 EBS 部分可了解更多内容。
您还需要将 fsx_setting 参数注释掉:
并将其替换为:
在使用 NFS 时,留意其会限制扩展性;当有成千上万的客户端需要同时访问文件系统时,FSx 特别有用。(如果您计划运行数个作业,每个作业使用多个节点,则此情形并不罕见。)
部署您的首个集群
现在您已经拥有了为 Ansys Fluent 创建首个 AWS ParallelCluster 的所有基础组件,您只需要将后安装脚本上传到您的 S3 存储桶中:
注:确保将您的后安装脚本上传到配置文件中指定的存储桶。
后安装脚本上传完成后,您可以通过运行以下命令行,使用先前定义的 ParallelCluster 配置文件创建集群:
注:如果这是您使用 AWS ParallelCluster 进行的首次测试,您需要额外的说明了解如何开始,则可以参阅这一篇 ParallelCluster 操作入门的博文,和/或 AWS ParallelCluster 文档。
安装 Ansys Fluent
现在是时候连接您集群的主节点,并安装 Ansys 套件了。您将需要使用先前命令输出结果中的公共 IP 地址。
您可以使用 SSH 和/或 DCV 连接主节点。
- 通过 SSH:
ssh -i /path/of/your/ssh.key centos@<public-ip-address> - 通过 DCV:打开浏览器并连接
https://<public-ip-address>:8443您可以使用“centos”作为用户名,并使用在后安装脚本中定义的密码。
在您登录后,获得 root 身份(sudo su - 或 sudo -i)并在 /fsx 目录下安装 Ansys 套件。您可以手动安装,也可以使用下方的示例脚本。
注意:我们已经在配置文件的 FSx 部分定义了 import_path = s3://<Your-S3-Bucket>。这将告知 FSx 从 <Your-S3-Bucket> 预加载所有数据。我们建议您预先向 S3 复制 Ansys 安装文件以及其他所有您可能用到的文件或软件包,这样所有这些文件都将位于集群的 /fsx 目录下供您使用。以下示例使用了 Ansys iso 安装文件。您可以使用 tar 或 iso 文件,这两种文件都可以从 Ansys 网站的“下载 → 当前发布版本”之下下载。
注意:如果您决定使用 EBS 共享选项,而非 FSx,则在 Ansys 安装完成后,您可能想要创建 EBS 卷的快照以便在其他集群中复用。您可以通过 web 控制台创建快照:
- 打开 Amazon EC2 控制台。
- 选择导航窗格中的快照。
- 选择创建快照。
- 在创建快照页面中选择要创建快照的卷。
- (可选)选择向快照添加标签。每个标签需要提供一个标签键和一个标签值。
- 选择创建快照。
如果使用 CLI:
如果您想要复用已有的快照,则在 AWS ParallelCluster 配置文件的 ebs 部分添加以下参数:
有关更多信息,请参见 Amazon EBS 快照。
运行您的首个 Ansys Fluent 作业
最后,您可以通过 qsub 提交以下脚本,来运行您的首个作业。以下是使用 14 C5n.18xlarge 实例运行作业的方法示例:qsub -pe mpi 360 /fsx/ansys-run.sh
ansys-run.sh可以是:
注意:您可能想要将基准文件 f1_racecar_140m.tar.gz 或其他想要使用的数据集复制到 S3,以便其能在 FSx 预加载供您使用。
小结
虽然此博文主要关注点为安装、设置、运行 Ansys Fluent,但也可将其中做法稍加修改用于运行其他 CFD 应用程序,以及其他使用消息传递接口 (MPI) 标准的应用程序,例如 OpenMPI 或 Intel-MPI。我们很乐意帮助您,代您在 AWS 上运行此等 HPC 应用程序,然后与您分享我们的最佳实践,您可以通过 AWS Docs GitHub 存储库或电子邮件随时随地提交您的请求。
最后,请不要忘记 AWS ParallelCluster 是一个以社区为中心的项目。我们欢迎所有人提交拉取请求或通过 GitHub 问题提供反馈。用户的反馈对于 AWS 来说极为重要,因为正是这些反馈推动了每一项服务及功能的发展!