亚马逊AWS官方博客
使用 GLUE 构建无服务器架构的 ETL Pipeline
ETL 是将业务系统的数据经过抽取、清洗转换之后加载到数据处理平台的过程,其目的是将企业中的分散、凌乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。众所周知,ETL 是 BI 项目重要的一个环节,通常在 BI 项目中 ETL 会花掉整个项目中至少1/3的时间。ETL 设计的好坏直接关系整个 BI 项目的成败。目前市场上主流的 ETL 工具譬如 Oracle 的 OWB、SQL Server 的 DTS 和 SSIS 服务、Informatic 等,它们要么通过单纯的 SQL 方式实现,屏蔽编码的复杂性,但是缺少灵活性,要么与后端数据源集成度不够高,缺少友好开发环境支持,对触发器,脚本化方面支持不够好。基于上面的 ETL 工具的不足,AWS 推出 Glue 服务可以很方便的解决上面的问题。AWS Glue 易于使用,内置常用的 Classifiers,轻松识别常用的数据格式,同时支持自定义 Classifiers,自动抽取多种数据源的元数据;完全托管的无服务器架构的服务,用户完全不用担心底层基础架构的故障,软件的更新,以及并发能力等,只需要将精力聚焦在如何提高 ETL 的效率方面;另外在开发编程环境,触发器,自动化脚本作业方面都提供很好的支持。
默认情况下,AWS Glue 提供的内置 Classifiers 如果不能满足数据抽取的需求我们需要创建自定义的 Classifiers,本文将演示如何通过 AWS Glue 构建无服务器架构的 ETL Pipeline 实现自定义文本识别器和将多个 CSV 文件在同一 Job 中完成数据的清洗,并将目标格式转换为 Parquet。
准备数据
选择数据源 Web 服务器的日志文件,演示如何自定义文本识别器。Web 服务器的日志样例格式如下:

该日志文件直接使用 AWS Glue 默认的文本识别器是无法识别的,类型显示是 unkonwn 的。
另外一个数据源是选择从公共数据集 NYTaxi 中下载的3个 Excel 文 件,演示如何在一个 Job 中实现批量转换多个表。该 Excel 文件样例格式如下:

创建自定义文本识别器
Step 1 创建 Metadata 数据库
打开 AWS Glue 服务的 Console,在左面的导航面板中选择 database,点击 Add Database,输入数据库名:testdb,如下图所示:

选择 create,数据库创建完成。
Step 2 创建 S3 bucket 用于存放源数据
打开 AWS S3 Console,点击 Create Bucket, 输入 Bucket Name: teetttt,如下图所示:

Step 3 创建自定义的 Classifiers
在 AWS Glue Console 左面的导航面板,选择 Classifier,点击 Add Classifier,输入 Classifier Name为errlog,选择 Classifier Type 为 Grok,输入 Grok pattern 为:
%{TESTTIME:timestamp} %{IPORHOST:login_host} \[\S+ %{USER:login_user}/%{NUMBER:pid} as %{USER:sudouser}/%{NUMBER:sudouser_pid} on %{WORD:tty}/%{NUMBER:tty_id}/%{IPORHOST:host_ip}:%{NUMBER:source_port}-\>%{IPORHOST:local_ip}:%{NUMBER:dest_port}\](?:\:|) (%{UNIXPATH:current_path} %{GREEDYDATA:command}|%{GREEDYDATA:detail})
Custom Pattern 为:
TESTTIME ([A-z][A-z][A-z] [A-z][A-z][A-z] [0-9] [0-9][0-9][:][0-9][0-9][:][0-9][0-9] [0-9][0-9][0-9][0-9])
如下图所示:
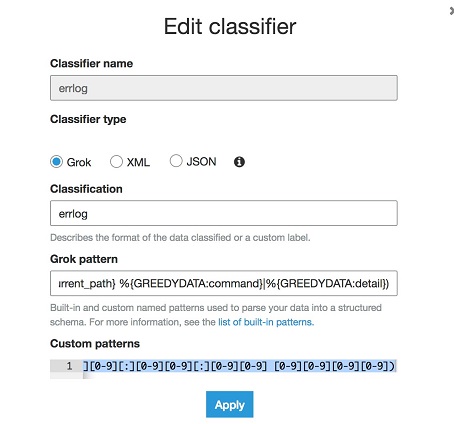
点击 Apply,配置完成。
注意在自定义 classifier 时,Grok 中支持的模式变量和 AWS Glue 中内置的正则变量可以直接在 Grok pattern 使用,譬如 GREEDDATA,UNIXPATH,USER 等。但是如果使用自己定义的正则模式变量,则需要在 Custom pattern 中定义,在本例中 TESTTIME 变量,由于默认的时间模式不能识别 Sun Mar 7 16:05:29 2004 日期格式,因而需要自己定义。
Step 4 创建 Crawlers,使用自定义的 classifier(errlog) 进行元数据爬取
在 AWS Glue Console 的左面导航面板中选择 Crawler,点击 Add Crawler,输入名称 customerrlog,自定义的 classifier 显示在页面下,如下图所示:

点击 Add,添加 errlog 到该 Crawler 中。
点击 Next,选择 Datastore 为 S3,指定 Step 2 创建的 bucket,如下图所示:

继续点击 Next,指定角色,允许该角色访问 S3:
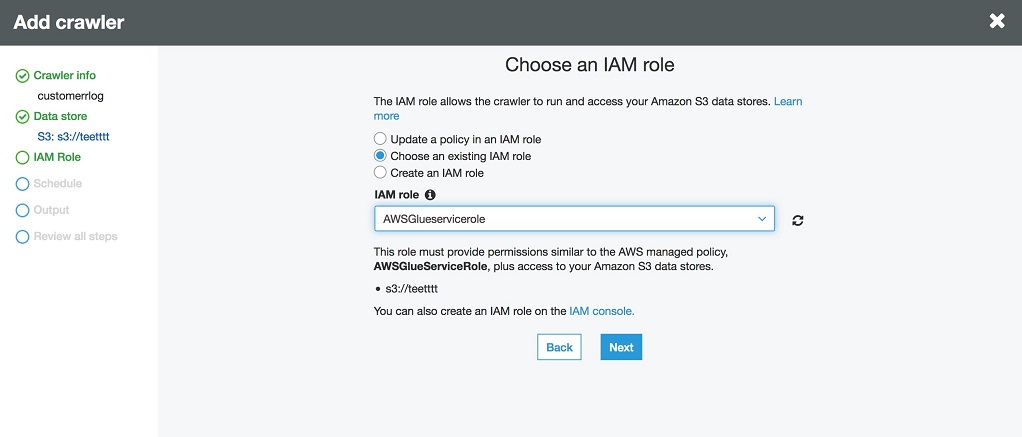
指定调度的频率为 Run On Demand,如下:
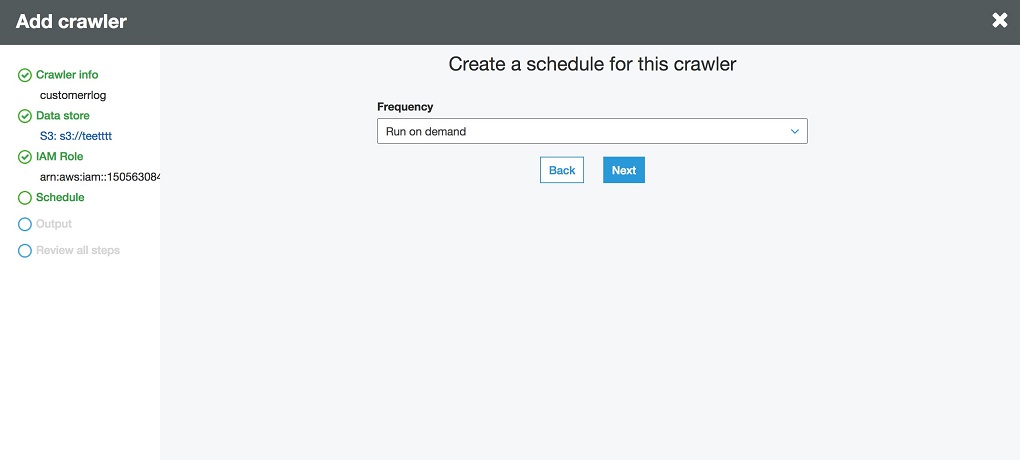
设置 Crawler 的元数据输出为 Step 1 中创建的数据库 testdb,如下:

继续选择 Next,review 信息无误,点击 Finish 创建完成。
Step 5 运行 Crawler(customerrlog),爬取 S3 bucket(teetttt)的数据
点击 Run Crawler,运行完毕,生成一个元数据表,如下图所示:

Step 6 调用 AWS Athena 浏览元数据表
选择 errlogbucket 表,点击 view data,AWS Glue 会自动调用 AWS Athena,显示元数据表,如下图所示:

日志文件通过自定义的 Classifier 抓取结果如下:

至此整个自定义 Classifier 对存储在 S3 上的数据进行爬取完成。这样用户可以根据元数据表的信息进行任意的数据转换和加载工作。
下面演示利用在一个 Job 中实现对多个元数据表数据进行清洗,由于 CSV 格式在大数据处理过程中效率相对于 parquet 稍差,需要将源数据(默认格式是 CSV 文件),转换为 parquet 格式,并再次写会到 S3 存储桶中。
创建一个 Job 实现对多个数据源文件进行清洗及格式转换
Step 7 创建 Crawler 命名为 crawlertaxidata,并创建 S3 数据输出存储桶
其具体操作方式参照上面的步骤介绍。
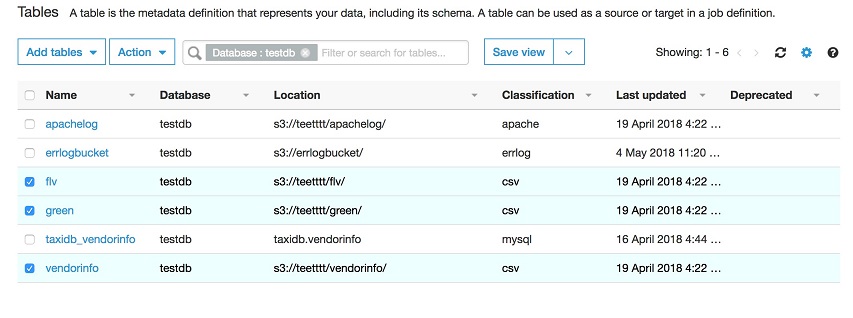
Step 8 运行该 Crawler,自动创建三张元数据表
分别为 flv, green和 vendorinfo,点击 View data 可以查看具体的元数据信息,如下图所示:
Step 9 创建 Job,实现单元数据表到单元数据表的数据抽取和转换
选择创建 Job,输入 Job 名称,指定 IAM Role,脚本的存储路径和临时路径,如下图所示:
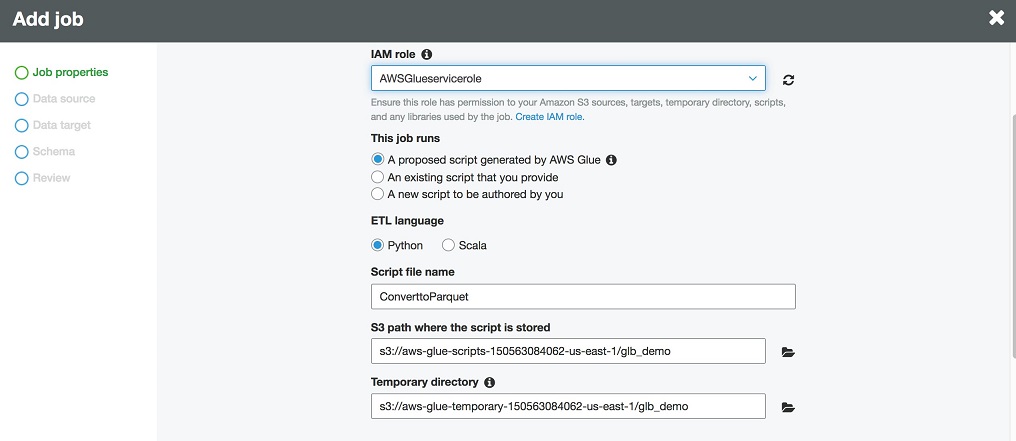
Step 10 选择元数据表
此处只允许选择一个元数据表,选择 green,如下图所示:

Step 11 选择目标数据输出的存储位置 S3 及格式 Parquet
如下图:

AWS Glue 支持5种输出格式,分别为 CSV,Parquet,ORC,Json,Avro。输出输出支持 S3 和 JDBC 两种方式。
Step 12 数据清洗及数据类型转换选择
根据需求自动进行数据的清洗及类型选择如下图所示:

Step 13 生成 Job 脚本,点击保存和编辑脚本
如下所示:
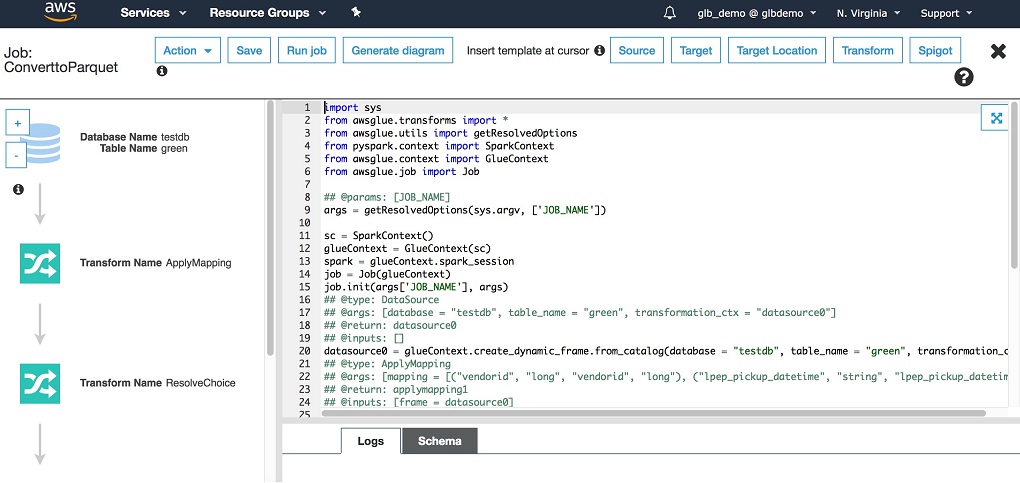
由于在实际项目中进行数据抽取的数据源会非常多,因为不能真对单个数据创建一个 Job,需要实现同一个 Job 进行多个数据源的转换操作,需要编辑脚本。
Step 14 编辑 Job 脚本,点击保存脚本
具体编辑完的脚本如下:
保存该脚本,点击 Run,完成数据的 ETL 工作。
结论
使用 AWS Glue 可以非常方便的帮助用户构建无服务器架构的 ETL Pipeline,用户不需要担心基础架构的可靠性以及后台的数据处理能力,只需专注于 Job 作业的编写。通过内置的 Classifier 和支持自定义创建 Classifier 两种方式为用户在数据爬取方面提供更大的灵活性,友好的脚本开发环境为用户的脚本开发和数据清洗提供更大便利。