亚马逊AWS官方博客
产品更新 – Amazon EC2 P3 实例多达 8 个 NVIDIA Tesla V100 GPUs 提供支持
自从我们于 2006 年发布最初的 m1.small 实例以来,在客户需求的推动以及不断发展的先进技术的支持下,我们后续推出了各种强调计算能力、超频性能、内存大小、本地存储和加速计算的实例。
新的 P3
现在,我们正在打造下一代 GPU 加速的 EC2 实例,这些实例将会在 4 个 AWS 区域提供。P3 实例由多达 8 个 NVIDIA Tesla V100 GPU 提供支持,可用于处理计算密集型的机器学习、深度学习、计算流体动力学、计算金融学、地震分析、分子模拟和基因组学工作负载。
P3 实例使用运行速度可高达 2.7 GHz 的 Intel Xeon E5-2686v4 定制处理器。有三种大小的实例可供选择 (所有均仅限 VPC 和 EBS):
| 模型 | NVIDIA Tesla V100 GPU | GPU 内存 | NVIDIA NVLink | vCPU | 主内存 | 网络带宽 | EBS 带宽 |
| p3.2xlarge | 1 | 16 GiB | 不适用 | 8 | 61 GiB | 最高 10 Gbps | 1.5 Gbps |
| p3.8xlarge | 4 | 64 GiB | 200 GBps | 32 | 244 GiB | 10 Gbps | 7 Gbps |
| p3.16xlarge | 8 | 128 GiB | 300 GBps | 64 | 488 GiB | 25 Gbps | 14 Gbps |
每个 NVIDIA GPU 都封装了 5,120 个 CUDA 核心和另外 640 个 Tensor 核心,最高可以提供 125 TFLOPS 的混合精度浮点、15.7 TFLOPS 的单精度浮点和 7.8 TFLOPS 的双精度浮点。在两种较大的实例上,GPU 通过以高达 300 GBps 的总数据速率运行的 NVIDIA NVLink 2.0 连接在一起。 这使 GPU 可以高速交换中间结果和其他数据,而不必使其通过 CPU 或 PCI-Express 结构进行。
什么是 Tensor 核心?
我在开始写这篇文章之前,从未听说过“Tensor 核心”这个词。根据 NVIDIA 博客上的这篇非常有帮助的文章的介绍,Tensor 核心是专为加快大型、深度神经网络的训练和推理而设计的。每个核心可以快速高效地将两个 4×4 半精度 (也称为 FP16) 矩阵相乘,然后将得到的 4×4 矩阵与另一个半精度或单精度 (FP32) 矩阵相加,最后将得到的 4×4 矩阵以半精度或单精度的形式存储起来。下面是摘自 NVIDIA 博客文章中的示意图:
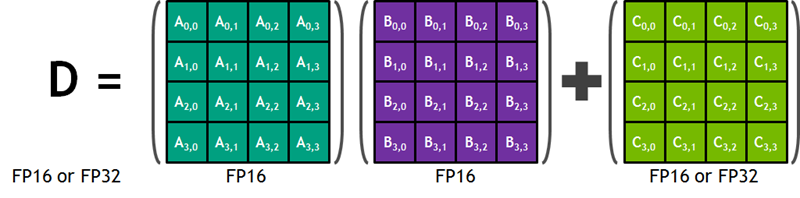
此运算发生在深度神经网络训练进程的最内层循环中,这个出色的示例展示了如今的 NVIDIA GPU 硬件是如何为应对非常具体的市场需求而专门打造的。顺便提一下,有关 Tensor 核心性能的混合精度这个限定词意味着,它非常灵活,完全可以处理 16 位和 32 位浮点值组合使用的情况。
性能视角
我总是喜欢将原始的性能数字放入到实际生活视角中,这样,这些数字与生活的关系就会更加密切,并且更有意义 (希望如此)。考虑到单个 p3.16xlarge 上的 8 个 NVIDIA Tesla V100 GPU 可以每秒执行 125 万亿次单精度浮点乘法,要将它与现实相联系就变得异乎寻常地困难。
让我们回到微处理器时代之初,想想我在 1977 年夏天购买的 MITS Altair 中的 Intel 8080A 芯片。该芯片使用 2 MHz 时钟频率,每秒可以执行大约 832 次乘法 (我使用了此处的数据并更正为更快的时钟速度)。p3.16xlarge 比该芯片快了大约 1500 亿倍。然而,从那年夏天到现在才过去了 12 亿秒。换言之,我现在一秒钟所做的计算,比我的 Altair 在过去 40 年里可以完成的计算的 100 倍还要多!
1981 年夏季发布的 IBM PC 有一种可选配件,那就是创新型 8087 算术协同处理器,它的情况又如何呢?该处理器使用 5 MHz 时钟频率和专门打造的硬件,每秒可以执行大约 52,632 次乘法。从那时到现在已经过去了 11.4 亿秒,而 p3.16xlarge 要比它快 23.7 亿倍,因此,这台可怜的小 PC 在过去 36 年里完成的计算量勉强才达到现在 1 秒钟可完成的计算量的一半。
好了,Cray-1 又如何呢? 这台超级计算机最早出现在 1976 年,执行矢量运算的速度为 160 MFLOPS,p3.x16xlarge 比它快了 781,000 倍。在推出以后的这些年中,这台计算机针对某些有意思的问题迭代改进了 1500 次。
考虑到您可以将 P3 视作一台超级计算机中可以根据需要启动的分步重复组件,因此更难将 P3 与现在的横向扩展型超级计算机进行比较。
立即运行一个实例
要充分利用 NVIDIA Tesla V100 GPU 和 Tensor 核心,您需要使用 CUDA 9 和 cuDNN7。这些驱动程序和库已经添加到最新版本的 Windows AMI 中,并且将会包含在计划于 11 月 7 日发布的更新的 Amazon Linux AMI 中。新的程序包已经在我们的存储库中提供,如果需要,您可以在您现有的 Amazon Linux AMI 上安装它们。
最新的 AWS Deep Learning AMI 将会预装在最新版本的 Apache MxNet、Caffe2 和 Tensorflow 中 (均支持 NVIDIA Tesla V100 GPU),并且在 Microsoft Cognitive Toolkit 和 PyTorch 等其他机器学习框架发布对 NVIDIA Tesla V100 GPU 的支持之后,AWS Deep Learning AMI 将会进行更新,以使用这些框架来支持 P3 实例。您也可以针对 NGC 使用 NVIDIA Volta Deep Learning AMI。
在美国东部 (弗吉尼亚北部)、美国西部 (俄勒冈)、欧洲 (爱尔兰) 和亚太地区 (东京) 区域,P3 实例以按需、竞价、预留实例和专用主机的形式提供。
— Jeff;