亚马逊AWS官方博客
在 Amazon Elasticsearch Service 中使用 Random Cut Forests 实现实时异常检测
异常检测是机器学习应用领域中的主要方向之一。我们可以使用多种数学及统计技术发现数据中的异常值,并以这种方法为基础开发出多种算法,在计算环境中实现异常检测。在本文中,我们将认真研究Amazon Elasticsearch Service与Open Distro for Elasticsearch中提供的异常检测功能的输出结果与准确性,并深入了解其中为什么要选择随机Random Cut Forests(RCF)作为核心异常检测算法。具体来讲,我们将:
- 讨论异常检测的目标。
- 分享如何使用RCF算法检测异常,以及为什么要选择RCF作为检测工具。
- 解释Elasticsearch异常检测的输出结果。
- 将此异常检测结果与其他常用方法进行比较。
什么是异常检测?
人类具有良好的直觉,能够快速判断出哪些地方出现了故障。通常,异常或者离群值会体现得非常明显,让人“一看就意识到这里出了问题”。但是,我们显然不能在计算型异常检测中继续沿用这样的直觉;相反,我们需要根据异常的数学定义进行跟踪筛查。
异常的数学定义是多种多样的,一般用于解决同正常观测相区别的概念。这种区别可以通过多种定义、以多种方式加以体现。其中一种常见的定义,就是“位于低密度区域中的数据点”。在跟踪数据源时,例如从特定IP地址传出的总字节数、特定网站上的登录次数或者特定产品每分钟的销售次数等,原始值中总会描述某种概率或者密度分布。其中的高密度区域,就是指存在数据点的可能性较高的区域;而低密度区域,则是指数据倾向于不出现的区域。关于更多详细信息,请参阅关于异常检测的一份调查报告。
例如,下图所示为轮廓图形式的二维数据,此轮廓图指示了区域内的数据密度。

图右下角的数据点明显出现在低密度区域当中,因此被视为异常迹象。当然,异常并不一定代表坏事。根据定义,异常准确来讲只是很少发生或者超出正常范围的情形,与好坏并没有直接关联。
Random Cut Forests与异常阈值
异常检测算法的核心包含两大主要部分:
- 一套用于估算输入数据流密度的RCF模型。
- 用于确定是否将目标点标记为异常的阈值模型。
大家可以使用RCF算法来汇总数据流,包括有效估计其数据密度,并将数据转换为异常度评分。异常评分是一个正实数,数字越大,则代表数据点的异常度越高。关于更多详细信息,请参阅在Open Distro for Elsticsearch中进行实时异常检测。
我们在这里选择RCF的原因包括:
- 流上下文——Elasticsearch特征查询具有流式特性,异常检测器每次只接收一个新的特征集合。
- 查询成本高昂——特别是在大型集群上,每一次特征查询都可能带来高昂的CPU与内存资源使用成本。这就限制了我们所获取的、可用于模型训练及初始化的历史数据量。
- 客户硬件——我们的异常检测插件与客户的Elasticsearch集群处于相同的硬件之上。因此,我们必须关注插件对CPU及内存资源的影响。
- 可扩展性——我们最好能将异常数据判断工作负载分配到集群上的各个节点当中。
- 未标记数据——即使出于训练目的,我们也无法在异常检测中访问已标记的数据。因此,算法本身必须为无监督形式。
根据以上各项约束以及跨多个数据域的内部与公开基准性能结果,我们选择了RCF算法耿计算数据流中的异常度得分。
但这又引出了新的问题:异常得分到底要高到什么程度,才足以将相应的数据点判断为异常?异常检测器使用阈值模型回答这个问题。这套阈值模型会将一段时间内观察到的所有异常得分信息,与RCF的某些数学性质结合起来。这种信息混合方法将使模型在所观察的数据量较少时,仍以较低的误报率做出良好的异常预测,结论趋势从长远角度看也与数据本体保持匹配。在本模型中,我们使用KLL Quantile Sketch算法为异常得分的分布建立起有效草图。关于更多详细信息,请参阅流中的最佳分位数逼近方法。
解读输出结果
异常检测器输出两个值:异常等级与置信度评分。其中异常等级属于对异常情况严重性的试题,范围在0到1之间。异常等级0代表的是数据点完全正常,而任何非0等级都代表着RCF输出的异常得分超过了分数计算阈值,因此存在一定程度的异常。根据本文开头提到的数学定义,等级与异常的密度成反比。即事件却罕见,其异常等级就越高。
置信度得分则是对异常检测模型在报告中固有误差范围之内的异常进行的概率度量。我们通过以下三个层面整理模型的置信度:
- RCF模型是否观察到具有统计学意义的数据度量。随着RCF模型所观察数据量的增长,这种置信度将逐渐接近100%。
- 置信上限来自阈值模型中分布图的近似值。KLL算法只能以特定的概率预测特定误差范围之内的得分阈值。
- 归因于Elasticsearch集群中各节点的置信度度量。如果节点丢失,则相应的模型数据也会丢失,并导致置信度暂时下降。
纽约出租车数据集
我们选择纽约市出租车乘客数据集,对这款新型异常检测器的功能进行了有效性验证。这部分数据来自纽约市过去6个月以来的出租车乘坐记录,时间窗口为30分钟。值得庆幸的是,这套数据集自带异常窗口标签,其中已经明确指示了已知异常事件的发生时间段。该数据集中的示例事件还包括纽约马拉松赛事以及2015年1月的暴风雪灾事件——前者结束后不久,出租车乘车率开始异常飙升,代表参加比赛的选手们都希望找机会歇歇;后者发生时,纽约市曾命令所有非必要车辆返回家中不得上路,乘车人数自然也大幅下降。
我们将异常检测器的结果与两种常见的异常检测方法进行了比较:基于规则法,与高斯分布法。
基于规则法
在基于规则法中,如果数据点超过了由人类指定的预设边界,则将被标记为异常。这种方法要求我们对传入数据拥有丰富而明确的认知,而一旦数据整体出现大幅度上升或下降趋势,则检测机制可能随之崩溃。
下图中的阴影部分,代表发生已知异常事件的纽约市出租车数据集对应周期。该模型将异常检测结果输出在出租车乘车值下方并显示为红色。一组人类标记者接收第一个月的数据(共1500个数据点),手动为其定义异常检测规则。有半数参与者表示,他们认为信息不够充分,不足以定义出可靠的检测规则。而从余下半数参与者提交的结果来看,异常规则应该是异常值等于或大于30000,或者在连续150个数据点(对应实际时间约3天)中低于20000。
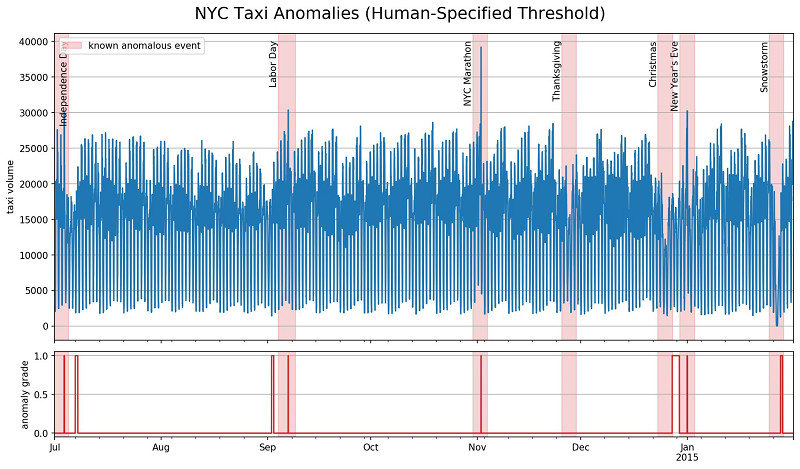
在此用例中,标记人员们给出的规则确实表现不错。但是,这种异常检测方法难以大规模扩展,而且可能需要大量训练数据才能让人们设置出合理的阈值,且保证不会受到误报或者漏报问题的影响。此外,如前所述,如果数据呈现出整体性的上升或者下降趋势,那么标记团队又需要重新审视数据内容并整理出新的固定阈值。
高斯分布法
第二种常见方法是将高斯分布拟合至数据当中,并将异常定义为距离均值三个标准差的任意值。为了提高模型适应新信息的能力,分布通常被放置在观察值的滑动窗口上。在这里,我们使用1500个最新数据点确定均值与标准差,并使用它们对当前值进行预测。具体如下图所示。
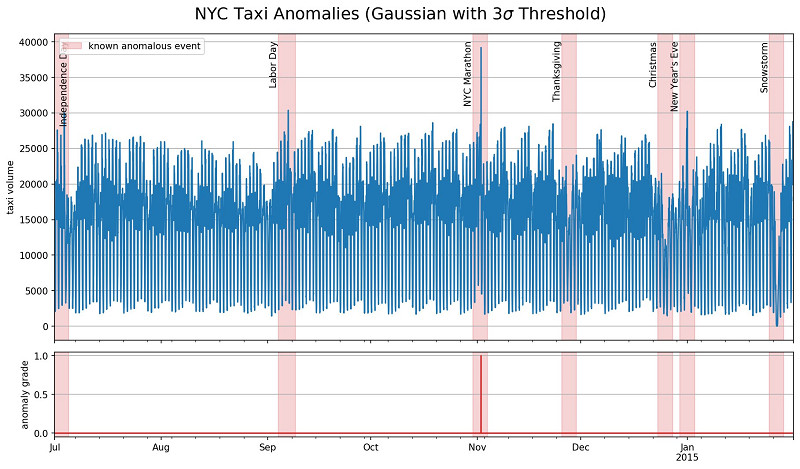
高斯模型在马拉松赛事期间检测到了明显的乘车高峰,但并不足以发现其他异常情况。通常来讲,这样的模型无法捕捉到某些特定类型的异常,例如突然出现但仍处于正常值范围内的数据飙升或者其他变化。
异常检测工具
最后,我们来看异常检测工具给出的异常检测结果。乘车数据被流式传输至RCF模型当中,该模型实时估算数据密度,并将这些异常得分发送至阈值模型,由阈值模型最终确定相应的数据点是否属于异常范围。以这样的思路为基础,模型通过异常级别对异常严重性进行了汇总与上报,具体参见下图。

我们的异常检测工具成为从7个已知异常事件中检测到了5个,误报数量为0。此外,我们还对异常等级做出明确定义,能够指出哪些异常相对来说更为严重。例如,纽约市马拉松赛事带来的乘车峰值,就要比五一劳动节以及新年夜的乘车高峰“严重”得多。根据数据密度异常的定义,纽约马拉松比赛中出现的情况处于密度极低的区域,代表其极为罕见。而在新年夜乘车峰值方面,虽然也比较少见,但发生机率要比马拉松比赛高得多。
总结
在本文中,我们理解了异常检测的目标,并探讨了异常检测模型与输出结果方面的详细信息。目前,大家可以轻松从Amazon ES以及Open Distro for Elasticsearch当中获得这些功能。最后,我们还将异常检测工具的结果与两种常用模型进行了比较,并观察到相当可观的性能改进。
本篇作者