AWS Database Blog
Migrating Autodesk’s mission-critical database from Microsoft SQL Server to Amazon Aurora MySQL
This is a guest post from Tulika Shrivastava, Software Architect from Autodesk, in partnership with Rama Thamman from AWS. In their own words, “Autodesk is a leader in 3D design, engineering, and entertainment software. If you’ve ever driven a car, admired a towering skyscraper, used a smartphone, or watched a great film, chances are you’ve experienced what millions of Autodesk customers are doing with their software.”
Autodesk started its cloud modernization journey years ago, moving workloads from private datacenters to Amazon EC2, among other AWS services. Autodesk needed to modernize to gain flexibility and scalability to support anticipated growth. In 2019, the company migrated its mission-critical single sign-on (SSO) application from self-managed SQL Server on EC2 to fully managed Amazon Aurora MySQL. This service funnels authentication requests from over 142 million users and responds to over 145,000 API requests per minute. It is integrated with over 300 products and services for authentication and authorization.
This migration helped streamline the management and resiliency of the Autodesk SSO service, optimize costs, and reduce overhead for infrastructure maintenance. According to an initial cost analysis, the company would save approximately 40% to 50% of overall database costs every month using Amazon Aurora MySQL.
This post outlines how Autodesk migrated this mission-critical database with minimal downtime. The following sections provide you with a view into pre-migration architecture, migration strategy, migration steps, and performance comparison.
Pre-migration architecture
The following diagram shows Autodesk’s previous SQL Server architecture. The database ran on self-managed EC2 instances. The configuration included the Always On feature spread across multiple Availability Zones and one node in another Region for disaster recovery.
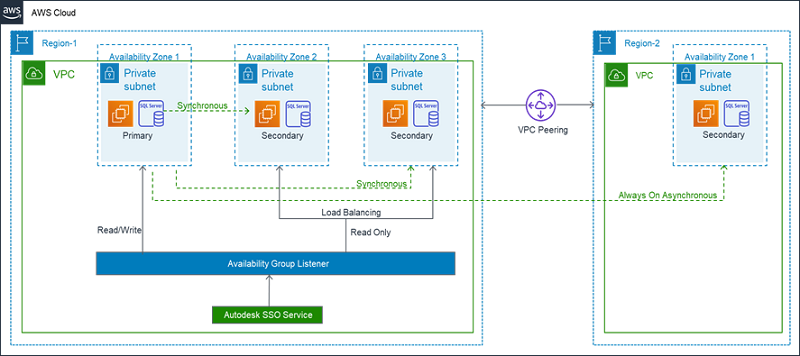
Over time, the team started facing the following challenges with the existing setup:
- Outages – Many of the incidents in the past were due to the self-managed complex database infrastructure, which involved EC2 instances having Amazon EBS storage with RAID 10 configuration. This resulted in problems in different layers, such as Windows Server Failover Cluster (WSFC), Storage, and IOPS. More importantly, it became challenging to do root cause analysis of the incidents.
- Backup – Managing backup was an overhead, particularly with cross-Region setup. Although we had used automated scripts, the process still required manual effort and monitoring.
- Patching – Because Autodesk has multiple environments (such as test, staging, and production), patching consumed a significant amount of our administrators’ time.
- Scalability – The primary node fields the read-only routing requests and identifies which secondary node it should get connected to. While this feature makes sure that connections are always routed to a healthy secondary node, it makes the primary node a bottleneck from a scalability standpoint.
- Number of replicas – SQL Server allows a maximum of 8 secondary replicas, whereas Aurora MySQL allows 15 replicas.
- Cost – The total cost of ownership was twice the amount compared to what we can achieve with migrating to Aurora.
- Elasticity – Scaling the infrastructure up or down was a time-consuming process.
Migration strategy
We started off the planning by conducting a proof of concept. This allowed us to identify application changes, database changes, scripting automation, and identifying the services that we can create ahead of time. More importantly, we were able to determine that migration to Aurora could resolve the previously mentioned limitations.
After we implemented the necessary changes, we created a plan to migrate different environments in a phased approach. This allowed us to fine-tune the strategy and get clear insights into the downtime we would incur when running the migration on different environments. The objective was to migrate with minimal downtime. To give us the flexibility in running the migration in different environments quickly and consistently, we automated elements such as database creation and DMS config using Terraform. You can also use AWS CloudFormation for automation.
The following sections discuss some of the key considerations.
Schema migration
AWS Schema Conversion Tool is an excellent tool to migrate schemas with minimal effort. In our case, we had to utilize our own schema conversion approach due to custom requirements.
As part of the schema conversion process, we selected the optimal character sets for the database. By doing so, our database size was reduced to almost a third of the original size. This was one of the major benefits.
You should evaluate the following options thoroughly before finalizing the schema for the target database:
- Charset and collation
- Data type choices
- Date/time pattern
- Multibyte character storage
- Special character storage
- Index types
These considerations not only help to migrate the data successfully, but also to avoid any post-migration problems with special datasets.
Capacity planning
We did extensive test runs for capacity planning. It involved running workloads iteratively to determine the suitable instance size and capacity; comparing key metrics from various monitoring tools such as Amazon CloudWatch, New Relic, and MonYog; and analyzing slow query logs. We also considered the existing production workload and future projection of traffic and data growth.
Application migration
Application migration was seamless because we used NHibernate (ORM) for data access. ORM generated approximately 80% of our queries, so we could make the application generate queries for MySQL with minimal changes in the ORM configuration. It’s always a good idea to know how many queries in your application are generated from ORM to estimate the effort needed to convert the rest of the queries.
We developed a feature in our SSO application to support on-demand database connection switching and for controlling read/write traffic. This helped us immensely in doing continuous deployment throughout the migration planning and execution on different environments. It also helped minimize the downtime involved during the database cutover.
We were using the full framework of .NET and, unfortunately, the MySQL driver for .NET full framework with NHibernate doesn’t support Aurora MySQL failover. This essentially means that the application can’t recover from such failure on its own. We came up with a custom solution to create a workaround for the missing support for Aurora MySQL failover in the .NET Driver for MySQL so the application can continue to serve the traffic without any failure.
Data migration
Data migration and validation is a critical step. We used AWS DMS, which helped us run the migration process securely and cost-effectively. For more information, see Getting Started with AWS Database Migration Service.
Migration steps
The following diagram outlines the various migration states and steps. This is a roll forward migration design pattern. These steps provide you insights into the migration progression. The following sections explain each state and what it involved.
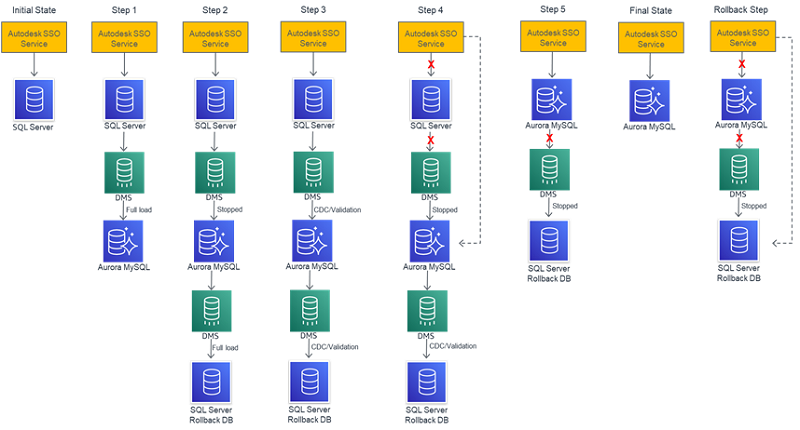
Wherever possible, we created the services and infrastructure ahead of time. For example, before we embarked on the migration, Aurora MySQL DB, SQL service rollback DB, and DMS instances were ready to go.
Initial state
This shows the initial state of the service with SQL Server.
Step 1
In this step, we started the full load migration from SQL Server to Aurora MySQL. Full load migration is a point-in-time snapshot copy. DMS copies the data from the source to the target.
For optimal full load performance from a database constraints inclusion perspective, it is ideal to have just the primary keys prior to the full load. You can add other constraints, such as foreign keys, after the full load. Because DMS loads data from multiple tables in parallel, complex foreign key relationships can slow down the process. On Aurora MySQL, it is best to have only the writer node. On the SQL Server rollback setup, it is ideal to have the rollback database created on the primary node. Index creation is faster if done on a single node, especially when there are big tables.
Step 2
After the full load task for SQL Server to Aurora MySQL was completed, we started the full load task for Aurora MySQL to the SQL Server rollback database. Upon completion of the task, we had full load data synchronized among the source, Aurora MySQL, and SQL Server rollback databases.
Step 3
In this step, we added indexes and foreign keys to both the Aurora MySQL and SQL Server rollback databases, added the reader nodes to Aurora MySQL, and added the rollback database to the Always On database. Adding these in this step helps improve full load performance and also makes the database Highly Available before cutover.
You can enable validation during the full load, but if you’re going to use change data capture (CDC), it is more efficient to enable it in this step. DMS takes care of data validation of the entire data, including data that was migrated as part of the full load. It has a special feature in which you can define custom validation functions. We used this feature heavily to validate special characters and blob data type.
As part of our QA process, we validated a few important workflows. We did a round of sample data validation after the full load to make sure that the key workflows worked as expected. This sample data validation was done on top of DMS validation. After thorough testing, the CDC was triggered to propagate the incremental changes that were accumulated since the full load from the source to Aurora MySQL, and Aurora MySQL to the SQL Server rollback database.
DMS sends migration metrics to CloudWatch. For more information, see Monitoring AWS DMS Tasks.
Step 4
While CDC was underway, we closely monitored the following metrics in CloudWatch, along with other metrics
ValidationPendingOverallCountCDCLatencySourceCDCLatencyTarget
When the validation pending overall count reached a low valueCDC latency between the source and target was at a minimum, we switched the database. It was a multi-step process. We stopped the write traffic for the application, waited for the pending records to be validated completely, and flipped the flag in the application to now point to Aurora MySQL.
Coming up with optimal value for the aforementioned metrics depends on the use case and the velocity of changes coming in. You need to determine those values through multiple rounds of test runs.
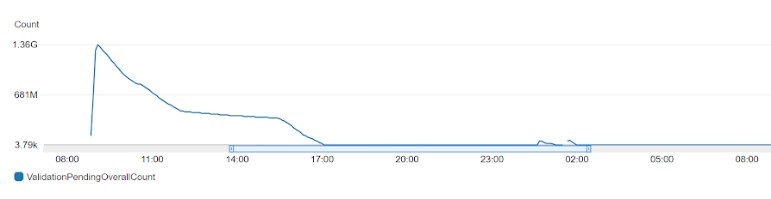
The following example graph shows the ValidationPendingOverallCount metric. You can see that the number of pending rows is high initially and it gradually comes down.
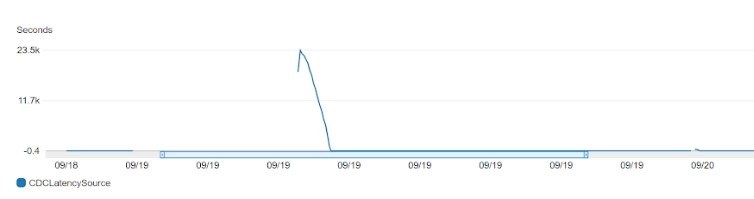
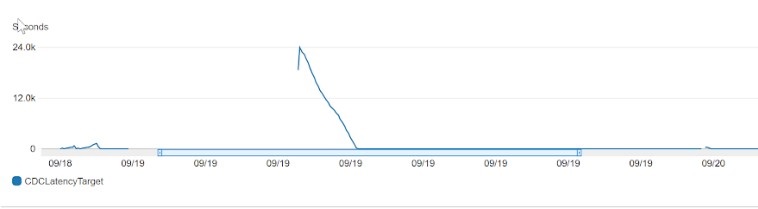
The following example graph shows the CDCLatencySource metric. It shows the gap, in seconds, between the last event captured from the source database and current system timestamp of the DMS instance. If no changes were captured from the source due to task scoping, DMS sets this value to zero.
The following example graph shows the CDCLatencyTarget metric. It shows the gap, in seconds, between the first event timestamp waiting to commit on the Aurora MySQL and the current timestamp of the AWS DMS instance. This value occurs if there are transactions that are not handled by Aurora MySQL. Otherwise, target latency is the same as source latency if all transactions are applied. Target latency should never be smaller than the source latency.
Step 5
In this step, our application was pointing to Aurora MySQL and functioning well. We had a team that tested the application end-to-end to make sure all the features worked as it should. We let the rollback setup run for a few days before stopping it.
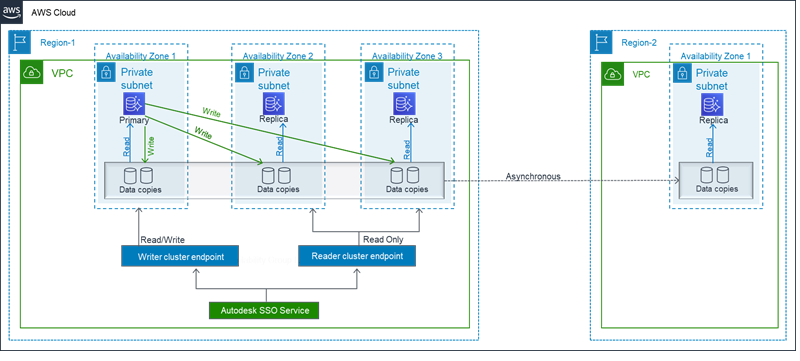
Final state
We removed the rollback setup in this step. The following diagram illustrates our new architecture.
Rollback step
This step was to have a backup plan in the worst-case scenario. Because the database is part of a mission-critical service, we had to put in mechanisms to recover from extreme worst cases.
In the event that we had to use this database, we planned to stop the write traffic to Aurora, wait for the pending records to get validated, and then switch the application to the rollback database (SQL Server Always On). This way we could go back to the old setup without any data loss.
It’s important to run enough tests to validate the rollback setup. We executed these tests with production-scale data in our test environment and made sure that there was no data loss when the application switched to use the rollback DB from Aurora MySQL.
Performance comparison
We captured top 10 query performance before and after the migration for both read and write queries.
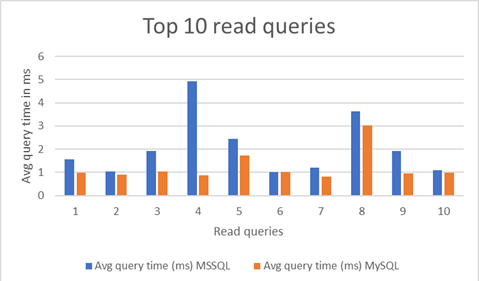
The following graph highlights the query performance for the top 10 read queries. You can see that Aurora performed exceptionally well.
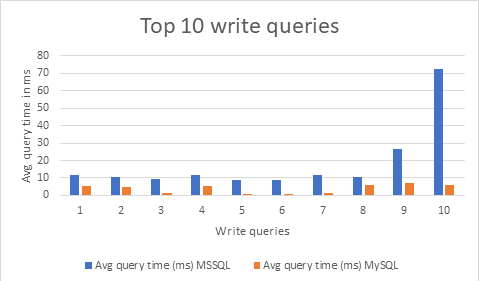
The following graph shows query performance for the top 10 write queries. Aurora MySQL outperformed MSSQL here as well. Execution times are considerably lower than MSSQL.
Recommendations
In addition to the approach outlined in the preceding sections, consider the following recommendations:
- Plan for many test runs so you can come up with a migration strategy that suits your database. There is no one-size-fits-all strategy, so come up with your own configuration and optimize accordingly.
- Conduct multiple rounds of performance testing to fine-tune SQL queries; they behave differently on different databases.
- Automate the migration process to the best extent possible. We used Terraform to automate, which allowed us to quickly repeat the test runs multiple times and come up with a consistent execution process.
- Set up all possible alerts and have ample monitoring in place to analyze the migration process.
- To give yourself enough time to handle unexpected errors, it is ideal to get to the database switching point (step 4 of the migration steps) at least a day before the scheduled cutover.
Conclusion
Heterogenous database migrations are not always easy, but with AWS DMS and proper planning, Autodesk had a smooth migration from SQL Server to Aurora MySQL. The company now has an infrastructure that provides significant operational efficiency and is optimized for cost and performance.
Given the benefits Autodesk and others have experienced with Amazon Aurora MySQL, what’s your plan for embracing transformation and modernizing your infrastructure?
About the Authors

Tulika Shrivastava is a Software Architect at Autodesk. She lives in Sydney and leads the single sign-on service for Autodesk. She has hands-on experience in designing and building scalable and highly available products and services, especially on AWS.

Rama Thamman is R&D Manager on the AWS R&D and Innovation Solutions Architecture team. He works with customers to build innovative prototypes in AI/ML, Robotics, AR VR, IoT, Satellite, and Blockchain disciplines.